
What worked — the chains that mattered
Several small issues, when chained, produced big impact:
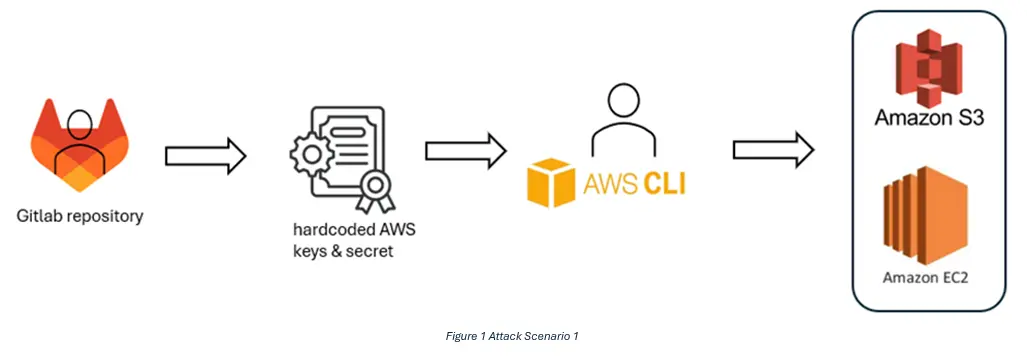
• Leaked long-lived AWS credentials in a repository: A set of AWS access keys committed into a repository accessible from dev allowed us to call AWS APIs. Those keys had enough privileges to enumerate and read resources in other accounts. This is the classic “one commit, unlimited impact” problem: secrets in code are readable by anyone with repository access.
• Hardcoded Docker registry auth on an EC2 instance: We found Docker auth stored on a dev EC2 instance. That credential allowed access to the private container registry that contained production images. Being able to download production images revealed sensitive configs and, where push permissions existed, creates a supply-chain risk.
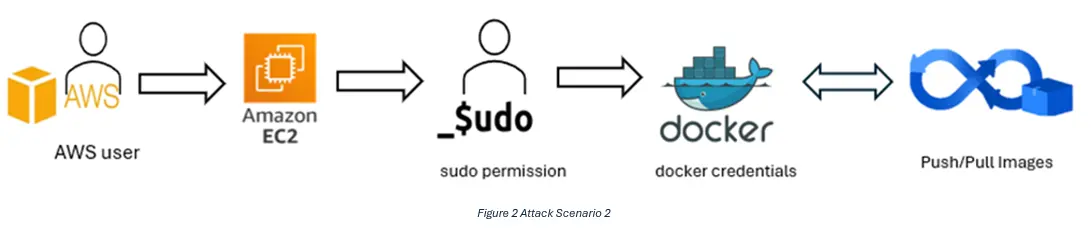
• Passwordless sudo: Several instances (including ones we could reach from dev tooling) allowed users to run sudo without a password. That meant any local account we could use could escalate to root on the machine with no additional authentication.
Chaining example (conceptual): exposed repo → obtain long-lived credentials → call AWS APIs to list cross-account roles/resources → use credentials found on an EC2 instance to access private registry → escalate to root on instance via passwordless sudo → pivot further.


